Oracle SQL和帆软学习笔记
记录学习SQL和帆软期间,一些重要知识点和语法。
一、SQL结构
SQL经典结构如下:
SELECT 字段名1, --数据表中的字段名称,每个字段名之间用半角“,”逗号隔开,为了美观和结构可换行
字段名2, --最后一个字段名后,不需要逗号
……
FROM 数据表名 --系统中的表,表可以进行重命名
WHERE 字段名1='值1'
AND 字段名2>'值2' --多个条件语句可用AND、OR连接
1. 缩进对齐和注释
首先要强调的是,无论是SQL或是其他编程语言,缩进对齐和注释是首要需要了解的。缩进对齐不仅是为了美观,更重要的是可以直观地了解层次结构,便于查阅过去自己写的或是他人的内容。适当的注释是为了便于更快速地理解写的内容,尤其是新字段或函数的定义与作用。所以,无论是初学者或是老手,书写时都应当适当的缩进对齐和添加注释,共勉谨记。
2. 函数命名
其次是无论是SQL或是其他编程语言,函数命名通常都与其英语单词有关,比如“Select”有“选择”之意,"From"有“从……”之意,“Where”有“在哪种情况下”之意,所以上述示例可理解为,从名为“数据表名”的数据表中,选择名为“字段名1”、“字段名2”的字段,条件是字段名1=值1并且字段名2>值2,将结果整理为一张新的表单内容。编程语言中使用的单词比较单一,且不同编程语言之前使用的单词大都相同,词汇量从来不是变成要考量的点,所以自己在命名新字段名称时,第一要避免与内置函数或方法名重复,第二是命名代表了新的字段的功能或意义,应当慎用诸如a、b、c等无实际意义的字母组合。
SQL中函数字母大小写没有区分,所以命名新函数、新字段不可单词重复,书写SQL查询语句时可以大写,也可以小写。
3. SELECT字段
后面跟随的是字段名,也就是列名。当使用聚合函数(SUM、AVG等)或者公式对字段进行了重新计算之后,可以将其重命名为新的字段,如:
SELECT COUNT(STUDENT_NAME) AS STUDENT_NUM FROM SCORE_LIST --设置字段别名
其中的AS可以省略不写。
-
当写为下面的形式时,表示将数据表中的所有字段取出:
SELECT * FROM SCORE_LIST --取出所有字段 -
当写为下面的形式时,表示取出其中的不重复数据:
SELECT DISTINCT CLASS FROM SCORE_LIST --取出重复数据
4. FROM字段
后面跟随的是数据表名,参考下表,格式为:表所在用户+.+表名+DB Link,例如:EDBADM. EDS_LOT_HIST或FABADM.LOTHISTORY@FAB2FR。当需要将表复制到BO时,DB Link中的FR需要修改为MDW,如:@FAB2MDW。
| 表所在用户 | 表名 | DB Link |
|---|---|---|
| EDBADM | EDS开头的表 | 不需要 |
| WEBADM | DM开头的表 | 不需要 |
| YMSADM | EDA开头的表 | @YMS2FR |
| FABADM | 如:TPFOMPOLICY | @FAB2FR |
| MOADM | @MOD2FR | |
| M2ADM | @M22FR |
5. WHERE字段
后面跟随的是条件,可以使用的逻辑函数有AND、OR、NOT,判断相关>、>=、<、<=、=、<>,、BETWEEN…AND…、IN、Like、||。
-
AND、OR可以相互组合成更为复杂的逻辑,例如:
WHERE (条件1 AND 条件2) OR (条件3 AND 条件4) -
=、<>、!=、^=:第一个表示等于,后面几个都表示不等于。
不同编程语言中,对此写法不一样,例如C语言中“=”表示赋值,只有“==”才是数学含义的相等,C语言中不等于记为“!=”。尤其需要注意的是>、<符号不能写为全角的>、<,>=、<=不能写为≥、≤,也就是字母和符号都是半角,通俗地说是英文输入法状态的符号。
-
BETWEEN…AND…:下面两种写法是等效的,都表示介于:
WHERE 字段1 BETWEEN '值1' AND '值2'相当于是:
WHERE 字段1 >= '值1' AND 字段1 <= '值2' -
IN相当于OR函数的简写,下面两种写法是等效的:
WHERE 字段1='值1' OR 字段1='值2' OR 字段1='值3'相当于是:
WHERE 字段1 IN ('值1','值2','值3') -
Like:该函数是SQL里面的通配符,SQL支持两种通配符:%和_,其中:
%表示0个或若干个字符,
_表示1个字符。
例如在数据表中有ABC、ABC1、ABC2、AB1、ABC123,当使用下面的查询时取出ABC、ABC1、ABC2、ABC123。
SELECT 字符 FROM 数据表 WHERE 字符 LIKE 'ABC%'当使用下面的查询时取出ABC1、ABC2,用“_”相当于同时限制了字符串的长度。
SELECT 字符 FROM 数据表 WHERE 字符 LIKE 'ABC_'需要注意的是LIKE的查询方式是模糊查询,通常存在效率问题,在数据量较大是,尽量避免使用Like。
-
||表示将多个字符串拼接为一个,WHERE条件中可以使用,SELECT字段中亦可使用。例如:
SELECT 字段名1||字段名2 字段名3 FROM 数据表表示将字段名1和字段名2拼接为一个字符串,并重命名为字段名3.
SELECT * FROM 数据表 WHERE 字段名1||字段名2 = '值1'表示取出条件为拼接之后的字符串为值1时的所有数据。
-
当然WHERE查询中还可以使用其他的函数配合查询,例如SUBSTR、LENGTH、regexp_like,但不能使用聚合函数(SUM、COUNT、MAX、MIN、AVG),具体函数语法与含义,后续讲解或搜索帮助。
6. GROUP BY
当在SELECT字段中使用了聚合函数(SUM、COUNT、MAX、MIN、AVG)时,需要指定计算时按照哪些字段进行汇总,比如是按照天别和设备别求和,或是设备别求最值,此时需要在WHERE所有条件之后补充GROUP BY,添加分组的字段。
例1,需要统计全校各班级各科目学生平均成绩,成绩表示例如下:
| Class | Student_Name | Subject | Score |
|---|---|---|---|
| 一班 | 张三 | 语文 | 92 |
| 一班 | 张三 | 数学 | 93 |
| 一班 | 张三 | 英语 | 89 |
按照需求,此处需要使用聚合函数:
SELECT CLASS,
SUBJECT,
AVG(SCORE) AVG_SCORE
FROM SCORE_LIST
GROUP BY CLASS,SUBJECT
--此段SQL可以不写WHERE条件,表示将数据表中所有数据取出
例2:一维表转为二维表,即整理为类似于下述的表:
| Class | Student_Name | 语文 | 数学 | 英语 |
|---|---|---|---|---|
| 一班 | 张三 | 92 | 93 | 89 |
| 一班 | 李四 | 94 | 88 | 89 |
使用下面的查询语句可以实现一维表转为二维表,重点是DECODE的使用,要求是数据表中没有重复的科目,即:数据表中不能有两行张三同学的语文成绩记录,否则求和之后将把两行成绩相加。
SELECT CLASS,
STUDENT_NAME,
SUM(DECODE(SUBJECT,'语文',SCORE,0)) 语文,
SUM(DECODE(SUBJECT,'数学',SCORE,0)) 数学,
SUM(DECODE(SUBJECT,'英语',SCORE,0)) 英语
FROM SCORE_LIST
GROUP BY CLASS,STUDENT_NAME
有时候SELECT字段中,需要按照不同维度进行汇总,比如既要计算各班级各科目学生平均成绩,分组条件为班级和科目,又要计算各班级人数,分组条件为班级,那么此时的分组条件是不一致的,就不能直接使用GROUP BY,而要使用OVER函数,将在后面的内容中说明。
7. ORDER BY
-
ORDER BY,顾名思义是按照……(次序)进行排序,将需要排序的字段罗列其后。比如上述成绩单需要依次按照班级、学生姓名排序,那么可以在WHERE条件语句后使用,有GROUP BY的须在其之后使用:
ORDER BY CLASS,STUDENT_NAMEORDER BY中可以指定字段按照升序或降序排列,默认为升序,当需要使用降序时,在字段名后添加DESC即可,如下按照各班级各学科成绩降序排列:
SELECT CLASS, SUBJECT, STUDENT_NAME, SCORE FROM SCORE_LIST ORDER BY CLASS,SUBJECT,SCORE DESC -
自定义排序
可以发现的是,排序结果里,班级是中文数字,生成的结果中并不是按照一、二、三依次排序,甚至有时候排得莫名其妙,默认中文排序一般与字符集相关,如果需要按照指定的顺序自定义排序,可以参考下面的写法:
ORDER BY DECODE(CLASS,'一班',1,'二班',2,'三班',3,'四班',4),SUBJECT,SCORE DESC班级和次序号绑定为一组数据,有多少班级需要排序,就在后面加多少组。当然该方法同样可以用于其他任意字符串的自定义排序。
-
中文排序
利用DECODE实现自定义排序的方法仅限于字符串内容已知,且数量较少时。如果数量多,可以参考下面的排序方式。
-
按中文拼音进行排序:SCHINESE_PINYIN_M
ORDER BY NLSSORT(字段名,'NLS_SORT = SCHINESE_PINYIN_M') -
按中文部首进行排序:SCHINESE_RADICAL_M
ORDER BY NLSSORT(字段名,'NLS_SORT = SCHINESE_STROKE_M') -
按中文笔画进行排序:SCHINESE_STROKE_M
ORDER BY NLSSORT(字段名,'NLS_SORT = SCHINESE_RADICAL_M')
-
8. HAVING
二、单引号与双引号
1. 单引号
-
引用字符常量,即在两个单引号之间输入常量字符的内容,例如:
SELECT * FROM SCORE_LIST WHERE CLASS='一班' -
转义符,对紧随其后出现的字符(单引号)进行转义。由于单引号在Oracle中已经被定义,想要使用单引号本身时,就需要进行转义,例如:
SELECT '''' FROM DUAL --结果为“'”,第二个单引号被作为转义符,第三个单引号被转义。 SELECT 'NAME''''' FROM DUAL --结果为“NAME''”,第2、4个单引号为转义符,第3、5个单引号被转义。 SELECT 'NAME'||'''' FROM DUAL --结果为“NAME'”,“||”表示字符串拼接
2. 双引号
-
字段名或别名中含有特殊字符或关键字,需要使用双引号包住。
SELECT 'beijing' "C S" FROM DUAL --字段名为“C S”,中间有空格 SELECT 'beijing' "from" FROM DUAL --字段名“from”为系统已定义关键字,需要引起来,另外还有date等 -
关键字、对象名、字段名、别名需要严格区分大小写时,需要使用双引号包住。
SELECT 'beijing' abc FROM DUAL --字段名没有引起来,Oracle会自动大写; SELECT 'beijing' "abc" FROM DUAL --字段名引起来之后,Oracle将严格区分大小写,非必要不应如此存数据 -
出现在to_char的格式字符串中时,双引号有特殊的作用, 就是将非法的格式符包装起来,避免出现ORA-01821: date format not recognized错误。 也就是说,去掉双引号和其包含的字符后,剩下的应该是一个合法的格式串。
SELECT TO_CHAR(sysdate,'hh24"时"mi"分"ss"秒"') results FROM DUAL --结果为“14时14分44秒”
三、数据类型
1. 字符串类型
-
固定长度类型(CHAR/NCHAR) :是指虽然输入的字段值小于该字段的限制长度,但是实际存储数据时,会先自动向右补足空格后,才将字段值的内容存储到数据块中;
-
可变长度类型(VARCHAR2/NVARCHAR2):是指当输入的字段值小于该字段的限制长度时,直接将字段值的内容存储到数据块中,而不会补上空白,这样可以节省数据块空间。
2. 数值类型
- NUMBER(P,S):可以存放数据范围为10130~10126;
- INTEGER:用来存储整数。若插入、更新的数值有小数,则会被四舍五入;
- Float(n):数n指示位的精度,可以存储的值的数目
3. 日期类型
- DATE:最常用的数据类型,日期数据类型存储日期和时间信息。虽然可以用字符或数字类型表示日期和时间信息,但是日期数据类型具有特殊关联的属性。为每个日期值,Oracle 存储以下信息: 世纪、 年、 月、 日期、 小时、 分钟和秒。一般占用7个字节的存储空间。
- TIMESTAMP:是一个7字节或12字节的定宽日期/时间数据类型,是DATE类型的扩展类型。它与DATE数据类型不同,因为TIMESTAMP可以包含小数秒。
4. LOB类型
5. LONG RAW&RAW类型
6. ROWID&UROWID类型
-
一般数据表里面存储的日期可能是DATE型,也可能是字符串类型,所以WHERE条件语句书写前需确认数据类型,根据类型可能需要使用TO_DATE或TO_CHAR转换数据类型,例如系统存的DAILY字段为字符串(8位年月日),那么WHERE条件语句参考下面的写法:
WHERE DAILY>='20221201' --直接使用字符串 AND DAILY<=TO_CHAR(sysdate,'YYYYMMDD') --需要转换数据类型如系统存的DAILY字段为日期型,那么WHERE条件语句参考下面的写法:
WHERE DAILY>=TO_DATE()'20221201','YYYYMMDD' --直接使用字符串 -
同样地,数据表存存储的数字可能是字符串类型,也可能是数值类型,在WHERE条件语句中进行判断时,也需要提前查看数据类型。例如:
WHERE NUM1>'0' --NUM1字段以字符串类型存储 AND NUM2>0 --NUM2字段以数值类型存储
四、函数及其语法
1. SUBSTR
语法:SUBSTR(string, pso,len),截取字符串中的一部分。
-- string:必需,指定的要截取的字符串;
-- pos:必需,规定在字符串的何处开始;
正数:在字符串的指定位置开始;
负数:从字符串结尾的指定位置开始;
-- len:截取的字符串长度,缺省即截取到结束位置;
示例:substr('123456',3,2),结果是“34”
substr('123456',3),结果是“3456”
substr('123456',-3,2),结果是“45”
通常结合TRIM除去字符串中的空格和不可见字符,例如:
TRIM(SUBSTR('123456',3)) --结果是“3456”,主要某些场景SUBSTR截取的字符串中会带有不可见字符,可通过LENGTH比对出
2. LENGTH
语法:LENGTH(string-expression),字符串长度。
--string-expression:字符串表达式,可以是列名、字符串文字或另一个标量函数的结果;
示例:length('123456'),结果是6;
同类函数还有LENGTHB(按照字节计算)、LENGTHC(按照Unicode计算)、LENGTH2(按照UCS2编码计算)、LENGTH4(按照UCS4编码计算)。
3. TO_DATE
语法:to_date(date_number,formula)将日期转为字符串。
--date_number:日期或时间,date型数据;
--formula:需要呈现的日期格式,不区分大小写;
Year:YY:2位数字的年份,如22;
YYY:3位数字的年份,如022;
YYYY:4位数字的年份,如2022;
Month:MM:2位数字的月份,如12;
MON:如12月,若是英文版,显示feb;
MONTH:如12月,若是英文版,显示December;
Day:DD:一个月中当中的日期数,如15;
DDD:当年第几天,如350;
DY:当周第几天简写,如星期五,若是英文版,显示fri;
DAY:当周第几天全写,如星期五,若是英文版,显示friday;
Hour: HH:小时,12小时制;
HH24:小时,24小时制;
MI:Minute (00-59).(分钟);
SS:Second (00-59).(秒);
Q:季度,如4;
WW:当年第几周,如50;
W:当月第几周,如2
年月日之间或时分秒之间可以使用其他符号链接,例如:
TO_DATE(sysdate,'YYYYMMDD HH24MISS') --结果是“20221231 122530”
TO_DATE(sysdate,'YYYY-MM-DD HH24:MI:SS') --结果是“2022-12-31 12:25:30”
--sysdate是生成系统默认当前时间,date型数据
4. TO_CHAR
TO_CHAR功能与TO_DATE相反,语法相似:to_char(date_string,formula),将字符串转为日期,例如:
TO_CHAR('20221231','YYYYMMDD') --结果是2022-12-31,日期型数据
5. DECODE
语法1:decode(expression,value,result1,result2),如果expression等于value,那么返回result1,否则返回result2,其中expression可以是表达式。需要注意的是该函数没有提供除等于以外的形式(大于、小于等),有这类需求时,可以使用CASE WHEN。例如:
SELECT DECODE(a,0,'零','非零') RESULT FROM DUAL --当字段a为0时,结果为“零”,否则为“非零”
语法2:decode(expression,value1,result1,value2,result2,value3,result3......,default),如果expression等于value1,返回result1,expression等于value2,返回result2,依次类推。
--default:若expression不等于所列出的所有value,则输出为default;
例如:
SELECT DECODE(a,'一',1,'二',2,'三',3,4) FROM 数据表
该用法可用于ORDER BY自定义排序。
6. CASE WHEN
用法:CASE WHEN 表达式1 THEN 表达式2 ELSE 表达式3 END AS 字段名。
多条件判断赋值,与DECODE的语法2不同的是,CASE WHEN可以自由书写表达式,实现任意判断,例如关于成绩等级的判断:
SELECT CASE WHEN SCORE >= 90 THEN '优' --成绩大于等于90分时,为优
WHEN SCORE >= 80 THEN '良' --成绩大于等于80分时,为良
WHEN SCORE >= 70 THEN '中' --成绩大于等于70分时,为中
WHEN SCORE >= 60 THEN '及格' --成绩大于等于60分时,为及格
ELSE '差' END AS GRADE --成绩小于60分时,为差,并将判断结果存到GRADE字段中
FROM SCORE_LIST
WHEN/THEN/ELSE后面的表达式可以自由组合,或者嵌套DECODE函数,甚至再套一层CASE WHEN用法。
7. IS (NOT) NULL
NULL通常搭配IS一起使用,当数据表中内容缺失数据时,WHERE查询语句中通常需要使用。如下一张表王五的成绩为空,这里的空既不是空格,也不是0:
| NAME | SCORE |
|---|---|
| 张三 | 80 |
| 李四 | 90 |
| 王五 | (null) |
使用下面的查询语句可以统计实际有成绩的学生人数,
SELECT COUNT(NAME) STUDENT_NUM
FROM SCORE_LIST
WHERE SCORE IS NOT NULL
8. NVL
语法:nvl(expression1, expression2),如果expression1为不为空,则返回expression1,否则返回expression2。
在4-7的例子中,如果计算学生平均成绩,可以写成下面这样:
SELECT AVG(SCORE) AVG_SCORE
FROM SCORE_LIST
--结果返回的是80和90的均值:85
但如果需要将缺考成绩置换为零分计算平均成绩,那么可以写成下面这样:
SELECT AVG(NVL(SCORE,0)) AVG_SCORE
FROM SCORE_LIST
--结果返回的是0、80和90的均值:56.67
NVL不仅可以用于字段的计算,还能在WHERE查询语句中使用:
SELECT COUNT(*) STUDENT_NUM
FROM SCORE_LIST
WHERE NVL(SCORE,0)<60
--统计不及格学生人数,结果为1
--当SELECT中只使用了聚合函数时,可不添加GROUP BY语句
9. INSTR
语法1:instr( string1, string2 ),查找string2在string1第一次出现的位置;
SELECT INSTR('helloworld','l') FROM DUAL --返回结果:3 默认第一次出现“l”的位置
SELECT INSTR('helloworld','lo') FROM DUAL --返回结果:4 即“lo”同时出现,第一个字母“l”出现的位置
SELECT INSTR('helloworld','wo') FROM DUAL --返回结果:6 即“wo”同时出现,第一个字母“w”出现的位置
语法2:instr( string1, string2 [, start_position [, nth_appearance ] ] ),从string1的start_position位置后开始查找string2字符串第nth_appearance次出现的位置。
SELECT INSTR('helloworld','l',4,2) FROM DUAL
--返回结果:9,在"helloworld"的第4(l)号位置开始,查找第二次出现“l”的位置
SELECT INSTR('helloworld','l',-1,1) FROM DUAL
--返回结果:9,在"helloworld"的倒数第1(d)号位置开始,往回查找第一次出现“l”的位置
INSTR可用于WHERE条件语句中,但查询效率相对较低。
10. JOIN、UNION
-
SQL Join
JOIN相关的包含全外连接Full Outer Join、左外连接Left (Outer) Join、、右外连接Right (Outer) Join和内连接Inner Join,四种Join方式可参考图示:
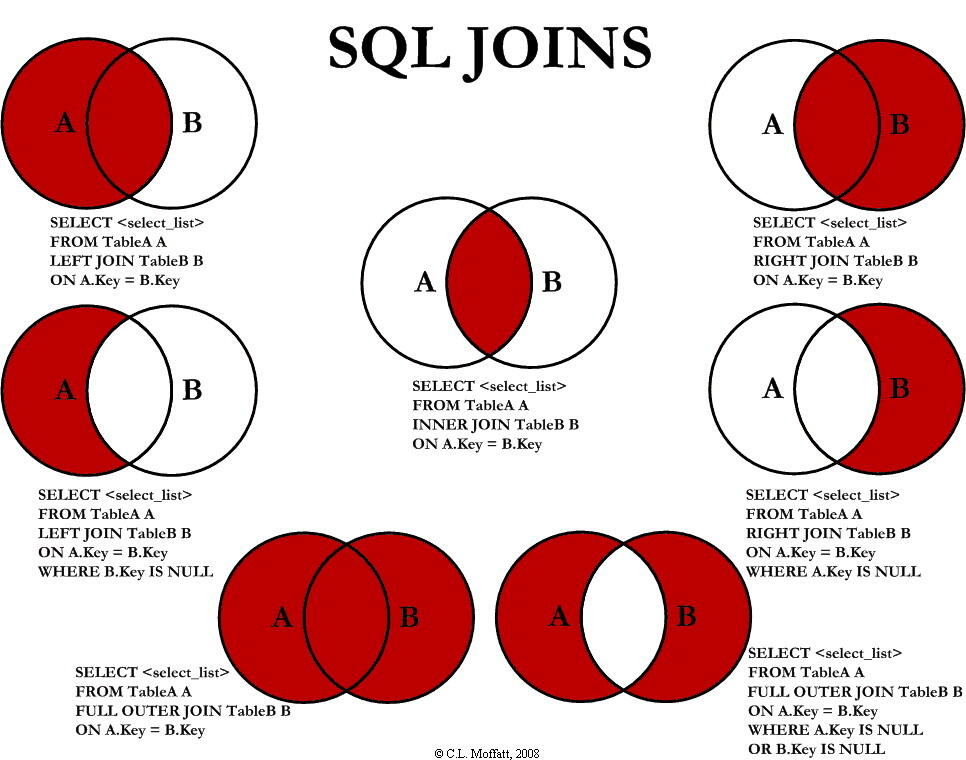
以左外连接为例进行说明:
SELECT A.*,B.* --选择A表和B表需要的字段 FROM TableA A --A表重命名 LEFT JOIN TableB B --B表重命名 ON A.key=B.key --表关联的条件,可以写多个A表与B表关联,关联的条件为A表中的Key与B表中的Key相等,最终呈现的表左表不加限制,保留左表的数据,匹配右表,右表没有匹配到的行中的列显示为null。Left Join和Right Join可以相互替换。
左外连接和右外连接的书写方式可以用“(+)”表示,例如左外连接可改为:
SELECT A.*,B.* --选择A表和B表需要的字段 FROM TableA A,TableB B --表重命名 WHERE A.key=B.key(+) --表关联的条件,可以写多个两种写法是等效的,被匹配的表写上“(+)”即可,如果是右外连接,那么就在A表写上“(+)”。
-
SQL UNION
UNION:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序。
UNION ALL:对两个结果集进行并集操作**,包括重复行,不会对结果进行排序**。
SELECT A.* FROM TableA UNION ALL SELECT B.* FROM TableB UNION ALL (SELECT * --合并子查询的结果,需要确认各查询的列数及其数据类型是否一致 FROM TableC C LEFT JOIN TableD D ON C.key=D.key )如上述查询,被合并的可以是子查询。
使用Union或Union All时,被合并的表,列数必须相同,列的数据类型也必须相同,列数不同时可以根据需要补充NULL值、''或0,如:
SELECT COL1,COL2,COL3 FROM Table1 UNION ALL SELECT COL1,COL2,NULL FROM Table2最后一个UNION ALL前面不能有ORDER BY ORDER BY只能在最后。
11. OVER分析函数
分析函数和聚合函数很多是同名的,意思也一样,只是聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。简单的说就是聚合函数返回统计结果,分析函数返回明细加统计结果。
语法:FUNCTION()OVER(PARTITION BY … ORDER BY …),此处的FUNCTION可以是下表中的函数,PARTITION BY表示分组,ORDER BY表示排序。OVER分析函数和GROUP BY可以共存。
| 函数名 | 功能 |
|---|---|
| SUM | 该函数计算组中表达式的累积和 |
| MIN | 在一个组中的数据窗口中查找表达式的最小值 |
| MAX | 在一个组中的数据窗口中查找表达式的最大值 |
| AVG | 用于计算一个组和数据窗口内表达式的平均值 |
| COUNT | 对一组内发生的事情进行累积计数 |
| - | - |
| RANK | 根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置 |
| DENSE_RANK | 根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置 |
| ROW_NUMBER | 返回有序组中一行的偏移量,从而可用于按特定标准排序的行号 |
| FIRST | 从DENSE_RANK返回的集合中取出排在最前面的一个值的行 |
| LAST | 从DENSE_RANK返回的集合中取出排在最后面的一个值的行 |
| FIRST_VALUE | 返回组中数据窗口的第一个值 |
| LAST_VALUE | 返回组中数据窗口的最后一个值 |
| LAG | 可以访问结果集中的其它行而不用进行自连接 |
| LEAD | LEAD与LAG相反,LEAD可以访问组中当前行之后的行 |
| - | - |
| STDDEV | 计算当前行关于组的标准偏离 |
| STDDEV_POP | 该函数计算总体标准偏离,并返回总体变量的平方根 |
| STDDEV_SAMP | 该函数计算累积样本标准偏离,并返回总体变量的平方根 |
| VAR_POP | 该函数返回非空集合的总体变量(忽略null) |
| VAR_SAMP | 该函数返回非空集合的样本变量(忽略null) |
| VARIANCE | 如果表达式中行数为1,则返回0,如果表达式中行数大于1,则返回VAR_SAMP |
| COVAR_POP | 返回一对表达式的总体协方差 |
| COVAR_SAMP | 返回一对表达式的样本协方差 |
| CORR | 返回一对表达式的相关系数 |
| - | - |
| CUME_DIST | 计算一行在组中的相对位置 |
| NTILE | 将一个组分为"表达式"的散列表示,创建的是等高直方图 |
| PERCENT_RANK | 和CUME_DIST(累积分配)函数类似 |
| PERCENTILE_DISC | 返回一个与输入的分布百分比值相对应的数据值 |
| PERCENTILE_CONT | 返回一个与输入的分布百分比值相对应的数据值 |
| RATIO_TO_REPORT | 该函数计算expression/(sum(expression))的值,它给出相对于总数的百分比 |
| REGR_(Linear Regression) Functions | 这些线性回归函数适合最小二乘法回归线,有9个不同的回归函数可使用 |
| - | - |
| CUBE | 按照OLAP的CUBE方式进行数据统计,即各个维度均需统计 |
| ROLLUP |
示例1:
SELECT CLASS,
STUDENT_NAME,
SUBJECT,
SCORE,
AVG(SCORE)OVER(PARTITION BY CLASS,SUBJECT) AVG_SCORE
FROM SCORE_LIST
--求各班各科目的平均成绩
在原有数据结果上,增加一列表示平均成绩,使用OVER分析函数,可以使用不同的分组和排序。
示例2:企业生产中,常常需要根据小时别的生产量,统计每个小时的累计量(第四列)。
| MACHINE | HOUR_TIME | PRODUCTION | SUM_NUM |
|---|---|---|---|
| 1# | 20221201 06 | 48 | 48 |
| 1# | 20221201 07 | 46 | 94 |
| 1# | 20221201 08 | 50 | 144 |
| 1# | 20221202 09 | 49 | 193 |
| 1# | 20221202 10 | 49 | 242 |
SELECT MACHINE,
HOUR_TIME,
PRODUCTION,
SUM(PRODUCTION)OVER(PARTITION BY MACHINE ORDER BY HOUR_TIME) SUM_NUM
FROM MACHINE_PRODUCTION_HOUR
12. LAG和LEAD偏移函数
语法:LAG(field, n, defaultvalue) OVER ( PARTITION BY … ORDER BY … ),LEAD语法与LAG相同,都需搭配OVER分析函数一起使用。
LEAD是查询下一行数据,LAG是查询上一行数据,其中n年时数据表偏移的行数。以前述企业小时别生产量为例:
SELECT MACHINE,
HOUR_TIME,
PRODUCTION,
LEAD(PRODUCTION,1,NULL)OVER(PARTITION BY MACHINE ORDER BY HOUR_TIME) NEXT_PRODUCTION,
LAG(PRODUCTION,1,NULL)OVER(PARTITION BY MACHINE ORDER BY HOUR_TIME) PRE_PRODUCTION
FROM MACHINE_PRODUCTION_HOUR
上述查询结果为:
| MACHINE | HOUR_TIME | PRODUCTION | NEXT_PRODUCTION | PRE_PRODUCTION |
|---|---|---|---|---|
| 1# | 20221201 06 | 48 | 46 | |
| 1# | 20221201 07 | 46 | 50 | 48 |
| 1# | 20221201 08 | 50 | 49 | 46 |
| 1# | 20221202 09 | 49 | 49 | 50 |
| 1# | 20221202 10 | 49 | 49 |
13. 排名函数
-
ROW_NUMBER
为查询出来的每一行记录生成一个序号,依次排序且不会重复,注意使用row_number函数时必须要用over子句选择对某一列进行排序才能生成序号。
-
RANK
与row_number函数不同的是,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,如:1、2、2、4。
-
DENSE_RANK
典型的中国式排名,rank函数生成的序号有可能不连续。dense_rank函数出现相同排名时,将不跳过相同排名号,如:1、2、2、3。
-
COUNT
count()是跳跃排序,例如出现相同排名时,会排成1、3、3、4的形式。
排名相关的函数需要使用OVER分析函数一起使用。举例说明,对成绩95、92、92、91、80分别使用四个函数进行排名:
--SCORE_LIST中SCORE字段成绩分别为95、92、92、91、80
SELECT ROW_NUMBER()OVER(PARTITION BY CLASS,SUBJECT ORDER BY SCORE) ORD1,
--结果为:1、2、3、4、5
RANK()OVER(PARTITION BY CLASS,SUBJECT ORDER BY SCORE) ORD2,
--结果为:1、2、2、4、5
DENSE_RANK()OVER(PARTITION BY CLASS,SUBJECT ORDER BY SCORE) ORD3,
--结果为:1、2、2、3、4
COUNT()OVER(PARTITION BY CLASS,SUBJECT ORDER BY SCORE) ORD4
--结果为:1、3、3、4、5
FROM SCORE_LIST
14. 正则表达式
函数主要有:regexp_like/regexp_instr/regexp_substr/regexp_replace。
用法上与LIKE、INSTR、SUBSTR 和REPLACE函数相同,使Oracle支持了正则表达式的语法,实现更为丰富的查找或替换。
WHERE NOT regexp_like(USER_ID,'^[0-9]+[0-9]$') --USER ID必须为数字
WHERE VALUE LIKE '1___6' --VALUE长度为5,开始和结尾分别为1、6
WHERE regexp_like(VALUE,'1...6') --VALUE长度为5,开始和结尾分别为1、6
SELECT REGEXP_INSTR('ABC123XYZ','[0-9]+') FROM DUAL --结果为4
SELECT REGEXP_SUBSTR('17,20,23','[^,]+',1,1,'i') FROM DUAL --结果是17
正则表达式语法主要符号标记如下:
- 非打印字符:
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
- 特殊字符:
| 特殊字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则$也匹配'\n'或'\r'。要匹配$字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 ?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 ^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \ |
- 限定符:
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于 {0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 "do" 、 "does"、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 "Bob" 中的 o,但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 "Bob" 中的 o,但能匹配 "foooood" 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 "fooooood" 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 |
15. WITH
当SQL查询中反复使用到同一段一模一样的子查询时,可以将该子查询放到WITH中作为对象引用,多个对象之间用半角逗号(,)隔开,并且将所有对象置顶。可参考下面的形式。
WITH T1 AS ( --从Table1生成T1,第一个对象有以WITH开头,其他不需要
SELECT *
FROM TABLE1
), --逗号隔开
T2 AS ( --从Table2生成T2
SELECT *
FROM TABLE2
), --逗号隔开
T3 AS ( --在T1基础上结合其他数据生成T3
SELECT *
FROM T1
WHERE C1='value'
)
SELECT * --在T3和T2的基础上处理,生成结果
FROM T3
LEFT JOIN T2
ON T3.key=T2.key
被引用的对象必须在当前查询语句之前,否则提示未定义。
16. LISTAGG
语法:ListAgg(字段名1,字符串)WITHIN GROUP(ORDER BY 字段名2),将多个值合并为一个字符串,需要搭配GROUP BY使用。例如:
LISTAGG(m.maskspecname,';')WITHIN GROUP(ORDER BY m.maskspecname) maskspecname
--返回值为“A;B;C”17. ### 创建临时表的两种方法
17. 创建临时表的两种方法
-
利用DUAL表和Union函数
DUAL表可以认为是虚拟表,建立数据库的时候随数据字典创建而建立的单行单列的表。主要介绍一下用途。
-
做临时的计算,例如输出系统时间或者进行四则运算。
SELECT sysdate FROM DUAL --获取系统时间,结果为2022-12-16 17:30:14.0 SELECT 1+1 FROM DUAL --进行四则运算,结果为2
-
-
创建临时表,可以使用Union或者Union All。
SELECT '1#' MACHINE, '20221201 06' HOUR_TIME, 48 PRODUCTION FROM DUAL UNION ALL SELECT '1#' MACHINE, '20221201 07' HOUR_TIME, 46 PRODUCTION FROM DUAL UNION ALL SELECT '1#' MACHINE, '20221201 08' HOUR_TIME, 50 PRODUCTION FROM DUAL UNION ALL SELECT '1#' MACHINE, '20221201 09' HOUR_TIME, 49 PRODUCTION FROM DUAL UNION ALL SELECT '1#' MACHINE, '20221201 10' HOUR_TIME, 49 PRODUCTION FROM DUAL -
使用Connect By创建一列临时表。
SELECT REGEXP_SUBSTR('ARRAY,CF,CELL','[^,]+',1,rownum) as col, REGEXP_SUBSTR('A,B,C','[^,]+',1,rownum) as col2 FROM dual Connect by rownum <= REGEXP_COUNT('ARRAY,CF,CELL','[^,]+') --生成3行2列的临时表数据
18. Unix时间戳
从1970年1月1日0点(北京时间为8点)开始所经过的秒数。
SELECT TO_CHAR(字段名/(3600*24)+TO_DATE('19700101 080000','YYYYMMDD HH24MISS'),'YYYY-MM-DD HH24:MI:SS') FROM DUAL
--Unix时间戳转Date型,手动修改时区
SELECT (sysdate-TO_DATE('19700101 080000','YYYYMMDD HH24MISS'))*3600*24 FROM DUAL
--Date型转Unix时间戳,手动修改时区
SELECT (sysdate-TO_DATE('19700101','YYYYMMDD'))*3600*24-TO_NUMBER(SUBSTR(TZ_OFFSET(sessiontimezone),1,3))*3600 FROM DUAL
--Date型转Unix时间戳,自动修改时区
帆软函数DateToNumber实现相似功能,不过是返回的毫秒数。
19. 系统数据表信息查询
--获取表字段:
select *
from all_tab_columns where table_name='FR_CF_NP_EN_BASE_INFO'
--获取表字段:
select *
from user_tab_columns
where Table_Name='FR_CF_NP_EN_BASE_INFO'
order by column_name
--获取表注释:
select *
from user_tab_comments
where Table_Name='FR_CF_NP_EN_BASE_INFO'
order by Table_Name
--获取字段注释:
select *
from user_col_comments
where Table_Name='FR_CF_NP_EN_BASE_INFO'
order by column_name
--当前用户的表
select */*table_name*/ from user_tables
--所有用户的表
select */*table_name*/ from all_tables
--索引查询
SELECT TABLE_NAME,
INDEX_NAME,
(SELECT LISTAGG( to_char(column_Name), ',') WITHIN GROUP(ORDER BY column_position)
FROM all_ind_columns c
WHERE 1=1
and i.INDEX_NAME=c.index_name
) col
FROM ALL_INDEXES i
WHERE TABLE_NAME = TRIM(UPPER('${tab}'))
AND TABLE_OWNER = '${Owner}'
五、帆软
1. 帆软公式和单元格相关
-
单元格隔行添加背景色,增强阅读性:
mod(row(), 2) = 1 -
帆软公式从查询中获取数据:
查询.SELECT(目标字段, 条件字段1 = "8FPHT07" && 条件字段2 = "F800-00")多个条件需要使用“&&”连接起来,如果返回结果是多个值,可以使用Count或Sum进行处理。
-
在单元格中插入了html相关内容时,如设置字体样式等,需要在单元格属性→其他→显示内容中选择“用HTML显示内容”,html分行的写法如下:
这是第一行<br>这是第二行 -
查询中使用帆软公式实现下拉框不选时,默认查询所有。
${=if(参数名="值","AND 字段名1= '"+参数名+"'","")}该内容补充到Where条件子句中,并且该行以前应当有其他子句,没有则补充上“1=1”,因为该行中用到了AND函数。
-
单元格使用SQL函数,获取查询结果。
SQL(connectionName,sql,columnIndex,rowIndex) --返回的数据是从 connectionName 数据库中获取的 SQL 语句的表中的第 columnIndex 列第 rowIndex 行所对应的元素。 =sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = '"+$$$+"' ",3,4) --传递的参数是获取当前单元格的值,即用 $$$ 作为参数时,字符串类型同样需要拼接单引号 =sql("FRDemo","SELECT * FROM STSCORE where CLASSNO in ('"+$class+"') and COURSE in ('"+$COURSE+"') ",3,4) --参数或者单元格值有多个的写法-- connectionName,据连接名字,字符串形式,需要用引号如"FRDemo";
-- sql,SQL语句,字符串形式,需要用双引号;
-- columnIndex,列序号,整型;
-- rowIndex,行序号,整型。(行序号可以省略,这样返回值为数据列)
2. 参数面板设置
-
隐藏参数面板小箭头。在参数面板的初始化事件中添加以下JavaScript脚本即可:
//延迟执行 setTimeout(function() { //隐藏参数面板小箭头 $('.parameter-container-collapseimg-up').hide(); }, 10); //删除参数面板小箭头 //$('.parameter-container-collapseimg-up').remove(); -
隐藏参数面板。决策平台引用报表、超链接引用报表、URL直连报表、单元格iframe等多种方式,在报表地址最后补充如下内容即可。
&__pi__=false -
参数面板删除按钮提交时二次确认
需要在参数面板绘制两个按钮,第一个是提示按钮,选择确认删除时,激活第二个按钮的操作,否则退出该过程。
第一个按钮添加点击事件如下:
FR.Msg.confirm("警告", "确定要删除吗?", function(value) { if (value) { _g().parameterEl.getWidgetByName("button0").fireEvent("click"); } });第二个按钮名称需与第一个按钮事件中一致,事件设置为删除提交,取消按钮可见性即可。
删除提交必须设置主键
-
参数面板提交按钮
增加按钮并添加点击事件:
_g().verifyAndWriteReport(); //_g('${sessionID}').writeReport(); //location.reload(); //初始化参数栏后,重新加载页面 contentPane.parameterCommit(); //参数栏不刷新,按所选查询条件刷新数据 alert("提交成功!"); FR.Msg.toast("提交成功!"); -
参数面板导出按钮
增加按钮并添加点击事件:
var url = FR.servletURL + "?op=export&format=excel&extype=simple&sessionID="+_g().currentSessionID; //原样导出 window.location =url;
3. 图表
-
图表联动,点击一个图表时,调整其他图表查询条件,实现互动。
第一个图表设置:单元格属性→特性→交互属性,超链接添加图表联动单元格为第二个图表左上角单元格地址,并添加参数,参数可以是分类名、系列名、公式等。

第二个图表设置:查询语句中,增加图表1的参数,可结合帆软IF函数实现未选中时默认全选。
-
图表显示标签使用JavaScript实现自定义。
主要使用了indexOf查找函数,substr字符串截取函数,toFixed四舍五入函数,示例如下:
function() { return this.category.substr(0, this.category.indexOf('No.')) + '<br>' + this.seriesName + ':' + (this.value / 60).toFixed(1) + 'min'; }
4. 报表参数
-
报表链接后增加参数“&bypagesize=false”可以实现不分页预览报表。例如:
/03.CF部/CF制造科/用户报表/98050035-杨柳/Movement/Coater流片履历.cpt&__bypagesize__=false -
报表预览情况下定时刷新
在模板→模板Web属性→分页预览设置,增加事件设置,写入以下JS脚本:
setInterval(function() { $(".vancharts-series-" + window.a).find("rect").css("stroke-width", "0.5") $(".vancharts-series-" + window.a).find("rect").css("stroke", "rgb(150,150,150)") }, 100) setInterval("self.location.reload();",1800000); //单位:毫秒;即每30min刷新一次页面其中setInterval的第二个参数设置时长,单位为毫秒。
-
天气JS
<iframe width="350" align="left" scrolling="no" height="30" frameborder="0" allowtransparency="true" src="https://i.tianqi.com?c=code&id=40&color=%2300B0F0&icon=1&site=12"></iframe> -
鼠标点击/悬浮行和列变色,再次点击/悬浮时恢复
菜单栏选择「模板>模板 Web 属性>分页预览设置」,选择「为该模板单独设置」,然后添加「加载结束事件」:
_g().addEffect('highlightCross',{ color: 'red', trigger: 'mousedown',//悬浮则为mouseover single:false });